Recent progress in machine translation has introduced a range of open-source neural models and general-purpose LLMs capable of translation, but their effectiveness often depends on model size and pretraining data quality. To overcome limitations with smaller models, ensembling techniques have become crucial. Traditional ensemble methods use static weight sharing, but modern approaches dynamically adjust weights based on the input sentence and candidate translation quality. These typically involve a candidate selection block (CSB) followed by a fusion block (FB) to combine outputs. However, requiring all L models to translate each input increases inference cost significantly, particularly problematic with LLMs. Furthermore, current CSB strategies are often ineffective at selecting optimal candidates. This work proposes a new ensembling strategy aimed at enhancing translation quality while reducing computational overhead compared to existing methods.
Building on the need for efficient and high-quality ensembling in machine translation, the paper introduces:
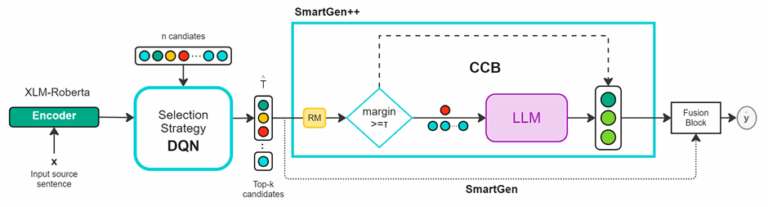
SmartGen: A DQN-based dynamic ensembling strategy that selects a subset of candidate models based on each source sentence, reducing inference cost by avoiding full-model evaluation.
SmartGen++: An enhanced variant that further boosts translation quality through a correction mechanism that selectively refines outputs using rejected candidates, achieving strong results with minimal additional cost.
Key Results:
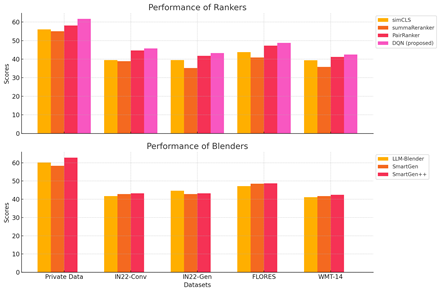
Table: Barplot showing the performance of our proposed method over other baseline ensembling methods in en-hi translation task.
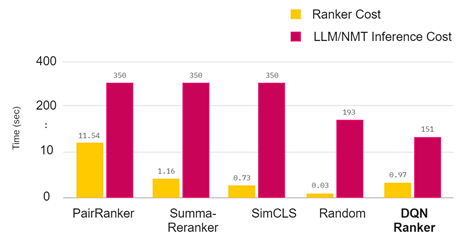
Fig: Demonstration of Inference Time Complexity/Cost among Rankers with their Ensemble LLMs Consumption; Reflecting DQN lowest Inference cost compared to baselines.
Conclusion:
This work addresses key shortcomings in current ensembling methods for machine translation by reframing candidate selection as a reinforcement learning task. By leveraging a Deep Q-Network (DQN), the approach dynamically selects optimal candidates for fusion, significantly reducing inference cost while improving translation quality through exploration. To mitigate the negative impact of weak candidates, the authors introduce a correction strategy that selectively refines translations at the cost of modest additional inference time. Extensive experiments across multiple benchmark datasets demonstrate that the proposed method consistently outperforms existing approaches, achieving state-of-the-art results across various evaluation metrics.
In most of the cases, it has been found that Content Driven sessions outperform the time driven sessions. The results are obtained on 6 baselines: STAMP, NARM, GRU4Rec, CD-HRNN, Tr4Rec on datasets like Movielens (Movies), GoodRead Book, LastFM (Music), Amazon (e-commerce).
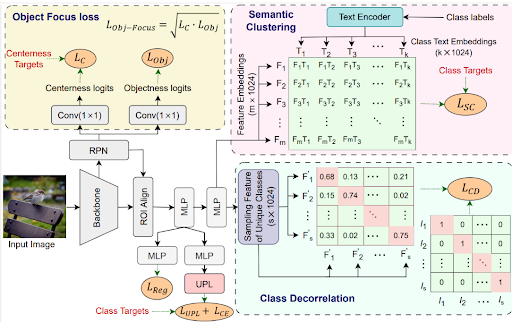
The introduced modules and techniques help the proposed method to align known class
representations effectively so that it can detect the unknown objects accurately. To validate
this, we carried out extensive experiments & ablation studies and found that the proposed
method outperforms existing SOTA methods with significant improvement on the MS-COCO
& PASCAL VOC dataset for the OSOD task.