Facial Landmark Detection (FLD) is a classic problem in Computer Vision with extensive
research having been carried out on this topic. While deep learning methods have led to
significant improvements in the performance on the FLD task, detecting landmarks in
challenging settings, such as head pose changes, exaggerated expressions, or uneven
illumination, continue to remain a challenge due to high variability and insufficient samples.
This inadequacy can be attributed to the model’s inability to effectively acquire appropriate
facial structure information from the input images.
To address above issue, we propose a novel image augmentation technique, specifically
designed for the FLD task to enhance the model’s understanding of facial structures. To learn
facial structures effectively, we try to leverage the ground truth landmark coordinates as an
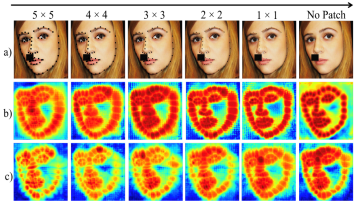
inductive bias for facial structure. To this end, we introduce n×n black patches around the
landmark locations in the training images, gradually reducing them over the epoch and then
completely removing them for the rest of the training, as illustrated in Fig 1. Since the
patches cover key semantic regions of the face, e.g., eyes, nose, lips and jawline, when the
model learns to predict these patches, it is able to learn the entire facial structure significantly
better, as compared to an architecture without this inductive bias. One could view this
augmentation technique as similar to Curriculum Learning (CL) [1], a strategy that trains a
machine learning model from simpler data to more difficult data, mimicking the meaningful
order found in human-designed learning curricula.