30th September 2024
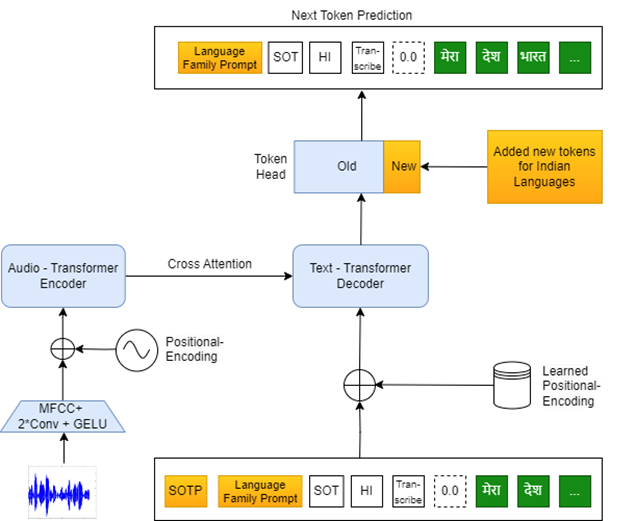
Overview of proposed framework
Kumud Tripathi summarises paper titled Enhancing Whisper’s Accuracy and Speed for Indian Languages through Prompt-Tuning and Tokenization co-authored by Raj Gothi, Pankaj Wasnik accepted at the ICASSP 2025.
Advancements in automatic speech recognition (ASR) have been driven by large foundational models like Whisper, which leverage multilingual speech recognition (MSR) to improve accuracy by utilizing linguistic similarities across languages. Modified Whisper models for Indian languages address these challenges by incorporating techniques like prompting to enhance recognition accuracy. Despite these advancements, Whisper’s effectiveness in Indian languages is hampered by deficiencies in tokenization. The tokenization process, which is crucial for ASR speed, affects low-resource languages more heavily. High-resource languages benefit from extensive token sets, whereas low-resource languages face slower inference times due to fewer tokens in the pre-trained Whisper tokenizer.

Table: WER (in %) and inference time (in min.) on Kathbath using Whisper Medium-based baseline and proposed models.
We demonstrate a significant advancement in multilingual speech recognition for Indian languages using the Whisper model. We have successfully improved the model accuracy for underrepresented Indian languages. By incorporating prompt-tuning with language family information, we leveraged linguistically related languages. Additionally, we introduced a new tokenizer to enhance the model’s efficiency in terms of inference time by reducing the number of generated tokens without compromising performance. Our consistently experiments show that both prompt fine-tuning and the proposed tokenizer individually outperform baseline ASR models, and their combination achieves an optimal balance between WER and inference speed. The resulting efficient Whisper model provides a flexible solution, enabling users to adjust the trade-off between accuracy and speed according to their specific application needs.
To know more about Sony Research India’s Research Publications, visit the ‘Publications’ section on our ‘Open Innovation’s page: Open Innovation with Sony R&D – Sony Research India
In most of the cases, it has been found that Content Driven sessions outperform the time driven sessions. The results are obtained on 6 baselines: STAMP, NARM, GRU4Rec, CD-HRNN, Tr4Rec on datasets like Movielens (Movies), GoodRead Book, LastFM (Music), Amazon (e-commerce).