In this blog, Brijraj Singh summarises the paper titled ‘Impulsion of Movie’s Content-Based Factors in Multi-Modal Movie Recommendation System’ co-authored by Prabir Mondal, Pulkit Kapoor, Siddharth Singh, Sriparna Saha and Naoyuki Onoe which was accepted at the International Conference on Neural Information Processing (ICONIP) in Changsha, China from 20th-23rd November 2023.
To know more about Sony Research India’s Research Publications, visit the ‘Publications’ section on our ‘Open Innovation’s page:
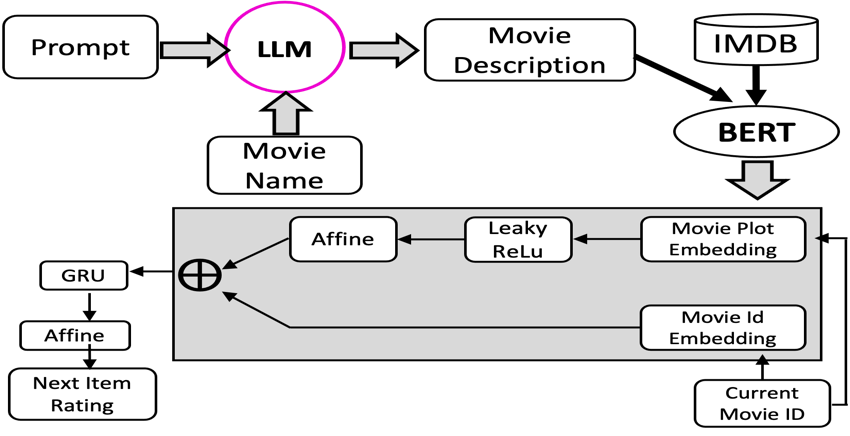
In this paper we explore movie recommendation and have established the concept (CDHRNN: Content Driven Hierarchical Recurrent Neural Network) of considering the description of the movie along with movie_Id which provides better recommendation performance because of the better representation of the items. The movie_Id or user_Id does not contain any information (as they are unique numbers) that can help in understanding whether two movies are similar or dissimilar by looking at their Id. Therefore, when they are considered with the description, the previous query can easily be answered, which helps in improving the recommendation performance. In the case of the video recommendation, where the item is a movie, finding the description/plot of the movie is not so challenging as it can easily be web-scrapped through a repository like IMDb. However, there could be a scenario when the description of the items cannot be crawled (considering other recommendation domains as well), in such cases we have proposed the use of LLM (Large Language Models), which receives exhaustive training of existing popular content. To be specific, we used Alpaca-Lora, and with the help of prompting which sets the context to provide the desirable description or plot of the movie. Since, the performance of LLM depends on its encounter with the online content at the time of training, it sets up a condition where only contemporary plots should be requested of the movies. If we query the plot of an old and unpopular movie, there is a chance that the model would not have received the training of that content and then it will try to provide the description based on its learning corresponding to similar items, which might not be relevant. This problem of LLM is known as hallucination when it provides the response based on irrelevant understanding. Hence, LLM helps in generating the content under certain assumptions.